반응형
순차탐색
- 리스트 안에 있는 특정한 데이터를 찾기 위해 앞에서부터 데이터를 하나씩 차례대로 확인하는 방법
- 보통 정렬되지 않은 리스트에서 데이터를 찾아야 할 때 사용
- 리스트에 특정 값의 원소가 있는지 체크할 때, 리스트 자료형에서 특정한 값을 가지는 원소의 개수를 세는 count()메서드를 이용할 때 순차 탐색 수행
#순차 탐색 소스코드 구현
def sequential_search(n, target, array):
for i in range(n):
if array[i] == target:
return i+1
print("생성할 원소 개수를 입력한 다음 한 칸 띄고 찾을 문자열을 입력하세요.")
input_data = input().split()
n=int(input_data[0])
target=input_data[1]
print("앞서 적은 원소 개수만큼 문자열을 입력하세요. 구분은 띄어쓰기 한 칸으로 합니다.")
array = input().split()
print(sequential_search(n, target, array))이진 탐색:
- 배열 내부의 데이터가 정렬되어 있어야만 사용할 수 있는 알고리즘.
- 데이터가 정렬되어 있을 때 매우 빠르게 데이터를 찾을 수 있다.
- 찾으려는 데이터와 중간점에 있는 데이터를 반복적으로 비교해서 원하는 데이터를 찾음 . 탐색 범위를 절반씩 좁혀가며 데이터를 탐색
- 이때 중간점은 시작점과 끝점의 소수점을 버린 인덱스. 시간 복잡도: O(logN), 데이터의 개수나 값이 1000만 단위 이상으로 넘어가면 이진 탐색과 같이 O(logN)의 속도를 내는 알고리즘을 떠올릴 수 있다.
이진 탐색 동작 예시
- 이미 정렬된 10개의 데이터 중에서 값이 4인 원소를 찾는 예시를 살펴보자

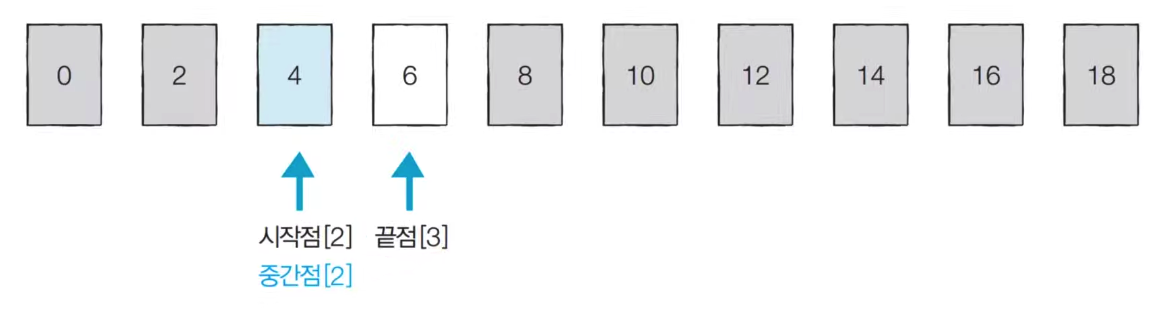
- [Step 1] 시작점: 0, 끝점: 9, 중간점: 4 (4.5에서 소수점 이하 제거). 이때 4와 8을 비교. 8이 더 크므로 이후의 값은 확인할 필요가 없다. 끝점을 3으로 옮긴다.

- [Step 2] 시작점:0, 끝점: 3, 중간점: 1 (1.5에서 소수점 이하 제거) 중간점에 위치한 2는 4보다 작으므로 2이하는 확인할 필요가 없다. 시작점을 2로 옮긴다,

- [Step 3] 시작점: 2, 끝점: 3, 중간점: 2 (소수점 이하 제거) . 4를 찾았으므로 탐색을 종료한다.
이진 탐색의 시간 복잡도
- 단계마다 탐색 범위를 2로 나누는 것과 동일하므로 연산 횟수는 log₂𝑁에 비례한다
- 예를 들어 초기 데이터 개수가 32개일 때, 이상적으로 1단계를 거치면 16개가량의 데이터만 남는다
- 2단계를 거치면 8개가량의 데이터만 남는다
- 3단계를 거치면 4개가량의 데이터만 남는다
- 다시 말해 이진 탐색은 탐색 범위를 절반씩 줄이며, 시간 복잡도는 𝑂(log𝑁) 을 보장한다
이진 탐색을 구현하는 방법: 1. 재귀 함수를 이용하는 방법 2. 반복문을 이용하는 방법
1. 재귀 함수를 이용하는 방법
def binary_search(array, target, start, end):
if start>end:
return None
mid=(start+end)//2
#찾은 경우 중간점 인덱스 반환
if array[mid]==target:
return mid
#찾고자 하는 값이 중간점보다 작은 경우 왼쪽 확인
elif array[mid]> target:
return binary_search(array, target, start, mid-1)
#중간점의 값보다 찾고자 하는 값이 큰 경우 오른쪽 확인
else:
return binary_search(array, target, mid+1, end)
n, target= list(map(int, input().split()))
array=list(map(int, input().split()))
#이진 탐색 수행 결과 출력
result=binary_search(array, target, 0, n-1)
if result==None:
print("원소가 존재하지 않습니다.")
else:
print(result+1)
2. 반복문으로 구현한 이진 탐색 코드
def binary_search(array, target, start, end):
while start<=end:
mid=(start+end)//2
#찾은 경우 중간점 인덱스 반환
if array[mid]==target:
return mid
#찾는 값이 중간점보다 작으면 왼쪽 확인
elif array[mid]>target:
end=mid-1
#찾는 값이 중간점보다 크면 오른쪽 확인
else:
start=mid+1
return None
n, target=list(map(int, input().split()))
#전체 원소 입력받기
array=list(map(int, input().split()))
#이진 탐색 수행 결과 출력
result= binary_search(array, target, 0, n-1)
if result==None:
print("원소가 존재하지 않습니다.")
else:
print(result+1)시간복잡도: O((M+N)*logN)
빠르게 입력받기
- 데이터의 개수가 1000만 개를 넘어가거나 탐색 범위의 크기가 1000억 이상이라면 이진 탐색 알고리즘일 가능성이 크다.
- 입력 데이터가 많은 문제는 sys 라이브러리의 readline()함수를 이용
- sys 라이브러리는 다음과 같은 방식으로 한 줄씩 입력받는다.
import sys
#하나의 문자열 데이터 입력받기
input_data=sys.stdin.readline().rstrip()
print(input_data)- sys 라이브러리를 사용할 때는 한 줄 입력하고 나서 rstrip() 함수를 꼭 호출-> 소스코드에 readline()으로 입력하면 입력 후 엔터가 줄 바꿈 기호로 입력되는데 이 공백 문자를 제거할 때 이용
rstrip()
문자열의 오른쪽 끝에서 특정 문자나 공백을 제거하는 함수입니다. 이 함수는 주로 문자열의 끝에 있는 공백을 제거할 때 사용됩니다.
text = "Hello, World! "
cleaned_text = text.rstrip()
print(cleaned_text) # 출력: "Hello, World!"
위의 예시에서 rstrip()은 문자열 "Hello, World!"의 오른쪽에 있는 공백을 모두 제거하여 "Hello, World!"를 반환합니다. 이 함수를 사용하면 문자열의 오른쪽 끝에 있는 불필요한 공백을 간단하게 제거할 수 있습니다.
'코딩 > 알고리즘' 카테고리의 다른 글
| 힙 자료구조, 우선순위 큐 (0) | 2023.02.23 |
|---|---|
| [이코테]8장_다이나믹 프로그래밍 (0) | 2023.02.20 |
| 알고리즘- 집합 자료형 이용 (0) | 2023.02.20 |
| 트리 자료구조 (0) | 2023.02.20 |
| 순차탐색 (0) | 2023.02.20 |
